
8 giugno 2026 · 11 min lettura
 Self-Hosting
Self-HostingZFS mirror, replica cross-node ogni 15 minuti, 5 job vzdump stratificati. Pensavo di essere protetto. Poi ho controllato davvero: il mirror non era un mirror, i backup stavano sulla root, e l'offsite era vuoto.
 Self-Hosting
Self-HostingPrometheus con 8 job, Grafana, node-exporter su ogni nodo e container, blackbox HTTP probe. E zero alert configurati. Il monitoring che raccoglie tutto ma non ti sveglia quando serve.

Iscriviti alla newsletter per ricevere i migliori articoli direttamente nella tua inbox.
Dal caso Yellow Tech alle PMI italiane: come l'AI generativa sta automatizzando contratti, fatture e workflow documentali B2B.
Installare Hermes Agent è un comando. Far convivere un LXC unprivileged, una GPU da gaming in passthrough, una scheda Turing e Ollama: è lì che si bruciano i weekend. Ho messo l'agente AI di Nous Research in un container Proxmox con una RTX 2070 Super da 8 GB, per avere un assistente 100% locale che non passa da nessun cloud. Funziona. Ma il pezzo difficile non è quello che pensi, e il modello giusto non è quello che ti aspetti.
Hermes Agent è il progetto open-source di Nous Research (licenza MIT, primo rilascio a febbraio 2026): non un wrapper di chat, ma un agente vero con learning loop, Curator autonomo, client MCP, gateway messaging e dashboard web. Io ho la v0.16.0, "The Surface Release", uscita il 5 giugno. Sotto, fa girare un LLM tramite un provider OpenAI-compatible. E qui parte tutto il divertimento, perché il mio provider non è un'API remota: è un Ollama che gira nello stesso container, sulla mia GPU.
Se vuoi il percorso senza GPU l'ho già raccontato altrove: Ollama in LXC senza GPU, i gotcha reali a 15 t/s CPU-only. Questo post è l'esatto contrario: stesso container Proxmox, ma con la GPU in passthrough, e si passa da 15 a 110 token al secondo. Il setup che ho costruito tiene tutto in casa: Hermes, Ollama e il modello vivono nello stesso LXC unprivileged, e la GPU fisica dell'host entra nel container in passthrough. Compatto, e proprio per questo fragile nei punti di giunzione. I pezzi:
Far entrare una GPU NVIDIA in un container LXC unprivileged è la parte che molti considerano "non fattibile", e la community Proxmox spesso consiglia di ripiegare su container privilegiati o VM. Si può fare in unprivileged, ma a due condizioni che nessun tutorial ti grida abbastanza forte: le librerie NVIDIA dentro il container devono combaciare esattamente con la versione del driver host, e devi passare i device giusti via cgroup. Sbaglia uno dei due e nvidia-smi muore senza spiegazioni utili.
Nel container non c'è il kernel module — quello vive solo sull'host. Quello che serve sono le librerie userspace, copiate a mano dall'host e con la versione identica a quella del driver (la mia 610.43.02): libcuda, libnvidia-ml e tutte le altre libnvidia-*, più symlink e ldconfig. Se l'host aggiorna il driver, queste lib vanno ricopiate o nvidia-smi smette di funzionare di colpo. Tienilo a mente prima di mettere gli aggiornamenti driver in automatico.
# config del container (/etc/pve/lxc/100.conf), lato host
lxc.cgroup2.devices.allow: c 195:* rwm
lxc.cgroup2.devices.allow: c 511:* rwm
lxc.cgroup2.devices.allow: c 236:* rwm
lxc.mount.entry: /dev/nvidia0 dev/nvidia0 none bind,optional,create=file
lxc.mount.entry: /dev/nvidiactl dev/nvidiactl none bind,optional,create=file
lxc.mount.entry: /dev/nvidia-uvm dev/nvidia-uvm none bind,optional,create=fileQuello che mi è costato più tempo: l'errore "PTX JIT compiler library not found". Non basta libcuda. Serve anche libnvidia-ptxjitcompiler, e se non la copi Ollama parte ma non compila i kernel a runtime. Un errore che ti manda a cercare nel posto sbagliato per ore, perché sembra un problema di CUDA e invece è una libreria mancante.
Una volta che nvidia-smi vede la scheda, pensi di aver finito. Non è così: il backend CUDA di Ollama su una GPU Turing nasconde due trappole che non trovi nella documentazione, solo negli issue tracker. La prima riguarda il backend che Ollama sceglie da solo, la seconda riguarda quanto modello ci sta davvero negli 8 GB. Entrambe finiscono con la GPU inattiva e una performance ridicola se non le conosci.
Da qualche release Ollama include un backend cuda_v13 che, su diverse schede, va in crash all'allocazione GPU. Sulla mia 2070 Super (Turing, sm_75) il sintomo è un segfault preciso in ggml_cuda_op_mul: Ollama parte e poi muore appena prova a usare la GPU. È un problema noto — gli issue lo riportano su un range di versioni tra la 0.13.0 e la 0.15.6, con stack trace che puntano all'allocazione di memoria sul device. Il workaround è lo stesso documentato dagli altri: disabilitare cuda_v13 e lasciare che Ollama ricada su cuda_v12.
# forza il fallback a cuda_v12 disabilitando la dir del backend instabile
mv /usr/lib/ollama/cuda_v13 /usr/lib/ollama/.cuda_v13.disabled
systemctl restart ollamaTentazione naturale: hai 16 GB di RAM nel container, perché non un modello da 14B? Perché su 8 GB di VRAM il 14B non ci sta, e l'offload ibrido è un disastro. Ollama mi caricava 29 layer su 41 sulla GPU e il resto in RAM; in un LXC le pagine mmap del modello vanno in thrash contro il limite del cgroup, e il risultato è stato 0,3 token al secondo con la GPU ferma allo 0%. Inutilizzabile. La regola dura che ne ho tratto: su 8 GB di VRAM si sta ≤8B parametri per girare interamente su GPU. Un 14B utile vuole più VRAM, non più RAM.
Qui arriva la decisione più controintuitiva di tutto il progetto, e il vero motivo per cui questo post esiste. Per il lavoro agentico con i tool, la documentazione di Nous è esplicita: Hermes richiede almeno 64.000 token di context, e rifiuta le finestre più piccole all'avvio (il default di Ollama, intorno ai 4k token, è troppo piccolo perfino per partire). Questo requisito, da solo, ribalta la logica con cui scegli il modello: non conta quanti parametri ha, conta quanto context regge su Ollama.
E qui qwen3:8b — il modello che istintivamente sceglieresti perché ha più parametri — è fuori dai giochi. Su Ollama è cappato a 40.960 token di context, sotto la soglia richiesta da Hermes. Non è lento come agente: è proprio inutilizzabile come agente, perché non arriva al minimo. Il qwen3:4b, invece, arriva a 262.144 token nominali. Il modello con meno della metà dei parametri è l'unico che può fare il cervello dell'agente.
| Modello | Context max nominale | Context usabile con Hermes (≥64k) | Verdetto come agente |
|---|---|---|---|

C'è un secondo gotcha annidato nel primo. A 64k di context il KV cache diventa enorme, e con la quantizzazione di default sborda dalla VRAM: con OLLAMA_KV_CACHE_TYPE=q8_0 il 4b mi caricava solo 30 layer su 37 sulla GPU. La quantizzazione del KV cache a q4_0 (che la doc Ollama dà a circa un quarto della memoria di f16, ma richiede flash attention attiva) fa entrare tutto: 37 layer su 37 su GPU, 5,4 GB occupati, full speed. È il compromesso che rende il tutto praticabile su 8 GB.
# /etc/systemd/system/ollama.service.d/override.conf
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=65536"
Environment="OLLAMA_KV_CACHE_TYPE=q4_0"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KEEP_ALIVE=-1"
Environment="OLLAMA_HOST=0.0.0.0"KEEP_ALIVE a -1 tiene il modello sempre residente in VRAM: per un agente che riceve richieste a raffica, pagare il caricamento a ogni turno sarebbe assurdo. Più context vuol dire KV cache più pesante; più parametri vuol dire pesi più grandi. Con 8 GB devi scegliere dove spendere il budget, e Hermes ha già scelto per te: il context vince.
I numeri che seguono sono miei, misurati oggi 8 giugno 2026 sulla stessa 2070 Super, via l'endpoint /api/generate di Ollama con num_predict a 400 e lo stesso prompt di coding per entrambi i modelli. Servono a rispondere a una domanda concreta: quanto paghi, in velocità, a usare l'8b al posto del 4b? E la risposta rende il paradosso ancora più netto, perché il modello che non puoi usare come agente è anche quello più lento.
| Modello (Q4_K_M) |
|---|
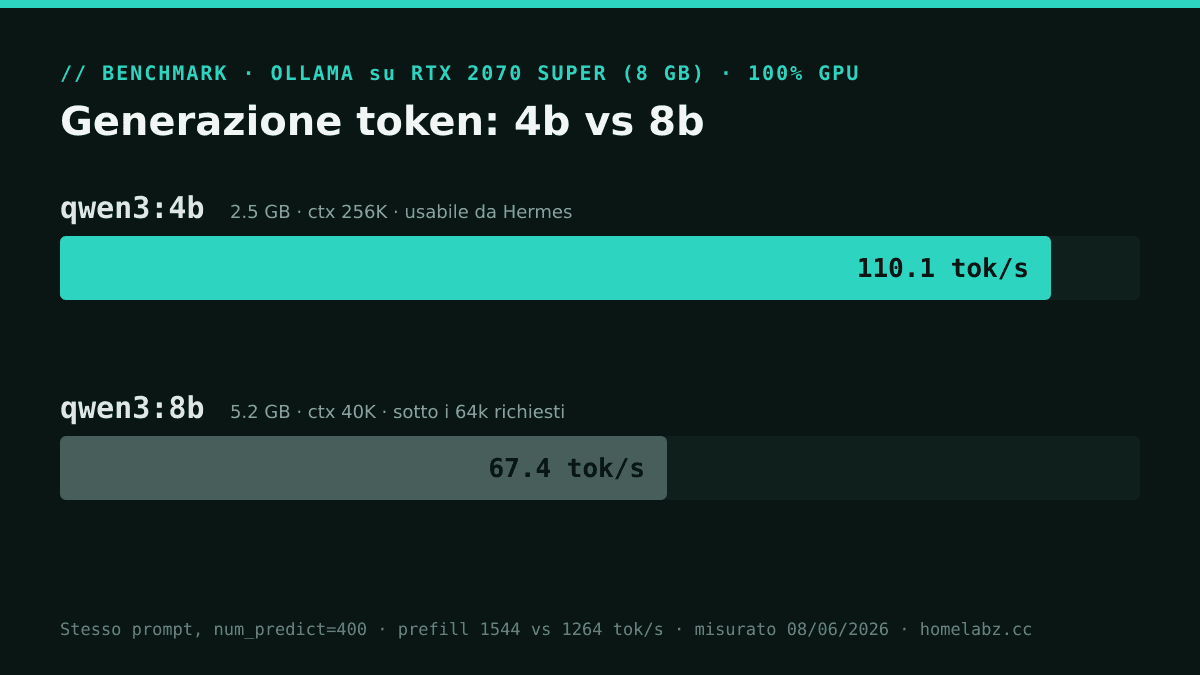
Entrambi girano interamente su GPU, niente offload su CPU: l'8b riempie esattamente i suoi 6,81 GB di VRAM al 100% sulla scheda. Il 4b è circa 1,6 volte più veloce in generazione. In un loop agentico, dove l'agente fa molti turni — ragiona, chiama un tool, legge il risultato, ragiona ancora — quei 110 contro 67 token al secondo si accumulano in fretta. Il 4b non è solo l'unico che regge il context: è anche quello che ti fa aspettare meno.
Per dare la scala: lo stesso tipo di carico su CPU senza GPU lo avevo misurato intorno ai 15 token al secondo con modelli ancora più piccoli. Il passthrough non è una comodità: è la differenza tra un agente che risponde e uno che ti fa fissare il cursore.
Con il modello giusto in VRAM, Hermes diventa quello che promette: un agente completo, non una chat. La dashboard web che servo dal container (systemd su porta 9119, tema terminale teal di Nous) ha sezioni per Chat, Sessions, Models, Logs, Cron, Skills, Plugins, MCP, Channels e Webhooks. C'è il Curator che cura la libreria di skill in autonomia su cron, il client MCP nativo, il gateway messaging per Telegram/Discord/Signal. È un agente vero, e si vede.
Due decisioni operative che ho dovuto prendere e che vale la pena rubare. La prima: la condivisione file. Hermes lavora in /workspace dentro il container, come root. Volevo montarci sopra l'NFS del NAS, ma il NAS ha root_squash e in un LXC unprivileged l'uid-mapping si rompe: Hermes scriveva file che poi rileggeva come nobody. Soluzione: niente NFS dal NAS, ma Samba servito dalla CT stessa con force user = root, montabile da Windows e da Linux. Controintuitivo — il NAS c'è apposta — ma con l'unprivileged è la strada che funziona.
La seconda: il backup. Ho un vzdump settimanale su nas-backup (snapshot + zstd), e il primo è uscito a circa 11 GB perché si è portato dietro tutti i modelli Ollama. I modelli si ri-scaricano in un comando: escludere /usr/share/ollama dal vzdump fa scendere il backup a 2-3 GB. Non backuppare ciò che ollama pull ti ridà gratis.
Devo darti il contrappunto, perché ometterlo sarebbe disonesto: la documentazione di Nous è contro la mia scelta. Per il tool-calling affidabile raccomanda un modello locale molto più grande del 4b, e avverte nero su bianco che i modelli piccoli (3B, 7B) a volte ignorano le istruzioni di tool-call e producono testo semplice invece di chiamare lo strumento. Hanno ragione. Un qwen3:4b come cervello agentico è una scelta dettata dal vincolo degli 8 GB, non l'ideale.
C'è anche la questione del context gonfiato: i 262.144 token nominali del 4b sono nominali. Gli studi sul context rot — fatti su modelli ben più grandi, Qwen3 incluso — mostrano che la qualità del ragionamento degrada con la lunghezza, e finestre lunghe possono cedere già intorno ai 50k token. Quindi il 4b regge i 64k richiesti da Hermes per partire, ma chiedergli ragionamento agentico multi-step serio a quella lunghezza è tirare la corda.
E nemmeno il conto economico torna, se è quello che cerchi: per un homelab personale il volume di token è ben sotto la soglia in cui il locale si ripaga rispetto al cloud (le analisi 2026 la mettono nell'ordine di milioni di token al giorno). Su questo fronte ho scritto perché un LLM locale si difende sulla privacy e la sovranità dei dati, non sul prezzo. È esattamente lì che questo setup ha senso: niente chiamate API, niente log su server di terzi, i tuoi dati restano nel tuo container. E se per te il bivio è un altro — cloud contro locale per il cervello agentico — l’ho ribaltato in un pezzo a parte.
Se parti da zero con Ollama prima ancora di pensare a un agente, la guida base ti porta a un'AI locale in dieci minuti. Da lì a Hermes su Proxmox il salto è grosso, ma ora sai dov'è il fango.
Quindi: ne vale la pena? Per imparare come funziona davvero un agente AI self-hosted sotto il cofano, per la privacy e la sovranità dei tuoi dati, sì, senza dubbi. Per sostituire un assistente serio in produttività agentica seria su una GPU consumer da 8 GB, no. E il setup vero, quello che ti porta via il sabato, non è installare Hermes — è quel comando. È far convivere GPU passthrough, LXC unprivileged, Turing e Ollama. Installare l'agente è l'ultima riga. Tutto il resto viene prima.
Fonti: Hermes Agent — doc setup Ollama locale (requisito 64k context), Hermes Agent releases (v0.16.0), Ollama FAQ (KV cache, flash attention, context length), Ollama qwen3 tags (context 4b vs 8b), Ollama issue #14188 (crash cuda_v13 → fallback cuda_v12), MindStudio — Local AI vs Cloud AI 2026 (breakeven, ibrido).
| qwen3:4b |
| 262.144 |
| Sì, regge i 64k richiesti |
| Usabile |
| qwen3:8b | 40.960 | No, sotto i 64k minimi | Inutilizzabile come agente |
| Generazione |
|---|
| Prefill |
|---|
| Tempo per 400 token |
|---|
| Residenza GPU |
|---|
| qwen3:4b (2,5 GB) | 110,1 tok/s | 1.544 tok/s | 4,24 s | 100% su GPU |
| qwen3:8b (5,2 GB) | 67,4 tok/s | 1.264 tok/s | 6,24 s | 100% su GPU (6,81/6,81 GB) |