Due anni fa, girare un LLM da 26 miliardi di parametri in locale richiedeva un rack, un budget enterprise e una tesi di laurea in CUDA. Oggi serve una GPU da gaming e tre comandi bash. Google ha lanciato Gemma 4 il 2 aprile 2026, e tra tutte le notizie sul lancio — benchmark, architettura MoE, multimodalità nativa — ce n'è una che ha catturato meno attenzione di quanto meritasse: la licenza Apache 2.0.
Non è un dettaglio tecnico. È un cambio di paradigma. Ogni iterazione precedente di Gemma aveva una licenza custom che poneva limiti sul deployment commerciale, sul numero di utenti, sull'uso in prodotti derivati. Con Apache 2.0, quelle restrizioni spariscono tutte. Puoi fare fine-tuning su dati proprietari, servire il risultato commercialmente, distribuire derivati — senza chiedere il permesso a nessuno. E questo, per chi gestisce un google gemma 4 homelab, cambia tutto.
Google Gemma 4 homelab: Apache 2.0 vale più dei benchmark
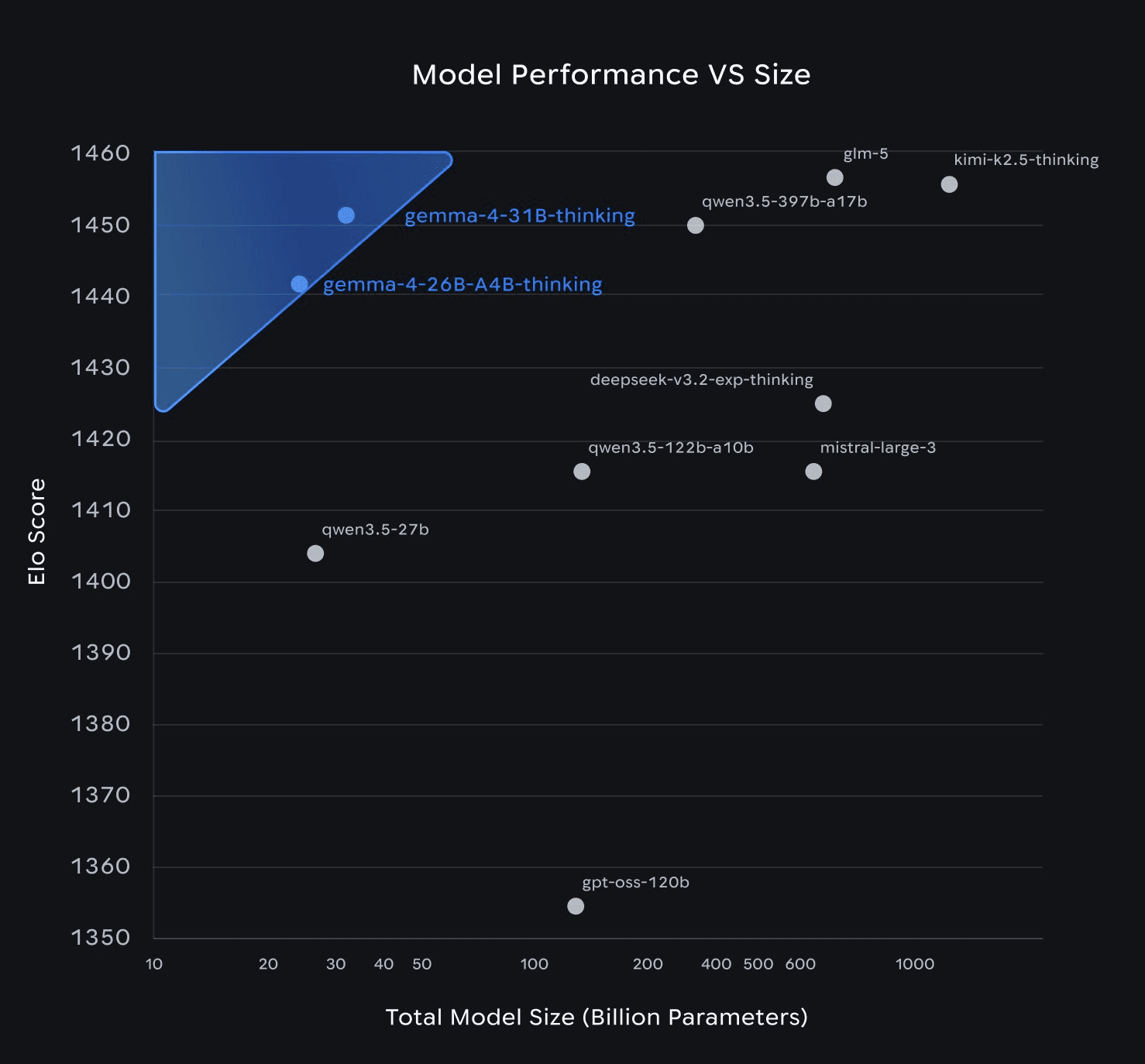
La narrativa ufficiale del lancio è centrata sui numeri: il modello 31B Dense raggiunge la posizione #3 tra tutti i modelli open mondiali su Arena AI con 1452 punti ELO, 89.2% su AIME 2026 (il 27B di Gemma 3 si fermava al 20.8%), 80.0% su LiveCodeBench. Sono numeri seri. Ma i benchmark vivono in ambienti controllati.
La community ha avuto 24 ore per spacchettare il lancio e le conclusioni sono state meno trionfali: il 26B MoE girava a 11 tokens/sec contro i 60+ tokens/sec di Qwen 3.5 35B su hardware identico. Il Dense 31B produceva solo "---\n" su qualsiasi input in LM Studio (bug risolto con aggiornamento, ma la prima impressione fa danni). Sebastian Raschka ha notato che l'architettura è "praticamente invariata rispetto a Gemma 3" — i guadagni vengono dal training recipe, non da innovazioni strutturali.
"Apache 2.0 removes the ambiguity that existed with the old Gemma license entirely. You can fine-tune it on proprietary data, serve the result commercially, share derivatives if you want, all without asking Google's permission." — Google Open Source Blog
Tutto vero. E tuttavia: Apache 2.0 su open weights con qualità al livello enterprise è un evento che si è verificato poche volte nella storia del settore. Quello che Google ha consegnato il 2 aprile non è il modello più veloce, né il più intelligente in assoluto. È il modello che hai il diritto di eseguire, modificare e distribuire senza che nessuno possa cambiare idea a metà corsa.